

突破Pytorch核心点,优化器 !!
嗨,我是小壮!
今儿咱们聊聊Pytorch中的优化器。
优化器在深度学习中的选择直接影响模型的训练效果和速度。不同的优化器适用于不同的问题,其性能的差异可能导致模型更快、更稳定地收敛,或者在某些任务上表现更好。
因此,选择合适的优化器是深度学习模型调优中的一个关键决策,能够显著影响模型的性能和训练效率。
PyTorch本身提供了许多优化器,用于训练神经网络时更新模型的权重。

常见优化器
咱们先列举PyTorch中常用的优化器,以及简单介绍:
(1) SGD (Stochastic Gradient Descent)
随机梯度下降是最基本的优化算法之一。它通过计算损失函数关于权重的梯度,并沿着梯度的负方向更新权重。
(2) Adam
Adam是一种自适应学习率的优化算法,结合了AdaGrad和RMSProp的思想。它能够自适应地为每个参数计算不同的学习率。
(3) Adagrad
Adagrad是一种自适应学习率的优化算法,根据参数的历史梯度调整学习率。但由于学习率逐渐减小,可能导致训练过早停止。
(4) RMSProp
RMSProp也是一种自适应学习率的算法,通过考虑梯度的滑动平均来调整学习率。
(5) Adadelta
Adadelta是一种自适应学习率的优化算法,是RMSProp的改进版本,通过考虑梯度的移动平均和参数的移动平均来动态调整学习率。
一个完整案例
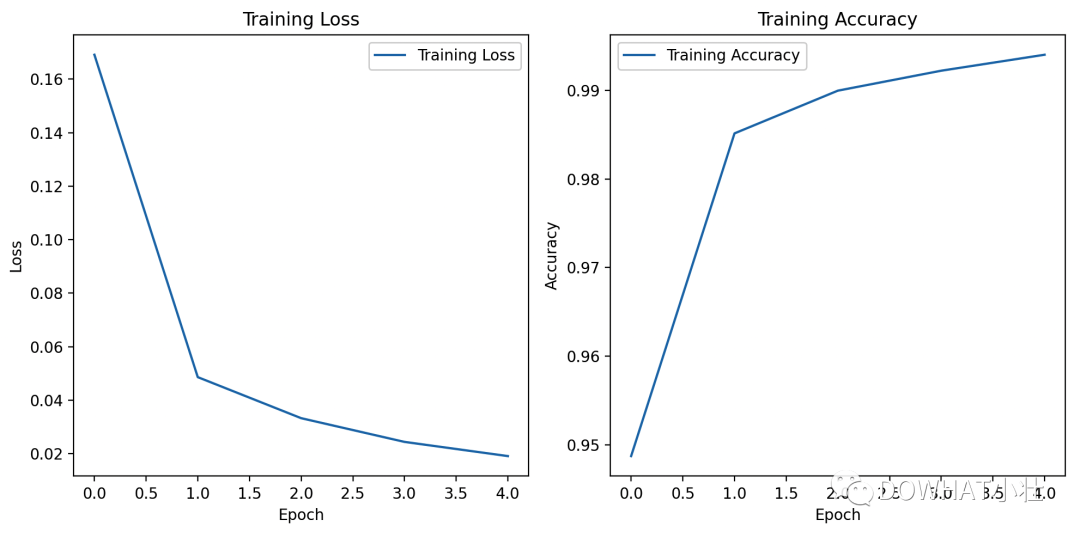
在这里,咱们聊聊如何使用PyTorch训练一个简单的卷积神经网络(CNN)来进行手写数字识别。
这个案例使用的是MNIST数据集,并使用Matplotlib库绘制了损失曲线和准确率曲线。
上述代码中,我们定义了一个简单的卷积神经网络(CNN),使用交叉熵损失和Adam优化器进行训练。
在训练过程中,我们记录了每个epoch的损失和准确率,并使用Matplotlib库绘制了损失曲线和准确率曲线。
我是小壮,下期见!


